
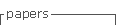









 Article in PDF format
Article in PDF format How to cite this paper
How to cite this paperAn. 2. Seminário Música, Cięncia e Tecnologia 2005
Medir o STI
Swen Müller
Instituto Nacional de Metrologia, Normalizaçăo e Qualidade Industrial (INMETRO). Divisăo de Acústica e Vibraçőes (DIAVI). Avenida Nossa Senhora das Graças, 50. Xerém - Duque de Caxias - RJ, 25250-020 – Brazil. smuller@inmetro.gov.br
RESUMO
No mundo inteiro, o STI (Speech Transmission Index) vem se tornando cada vez mais importante para a avaliaçăo da inteligibilidade em lugares públicos. Muitas vezes, o STI já faz parte dos requerimentos do cliente ŕ construtora de uma nova edificaçăo. Se o STI năo estiver acima de um valor mínimo no prédio concluído, a construtora terá que adotar medidas para melhorar a qualidade acústica do recinto, senăo estará sujeita a pena contratual. Por isso, o STI já tem sido avaliado na fase de planejamento por softwares de simulaçăo para conferir a viabilidade dos requerimentos. Após a construçăo, os resultados săo verificados mediante mediçőes “on site”. Este artigo pretende descrever os conceitos fundamentais do STI e apresenta a técnica e o processamento para obtę-lo. Alguns exemplos teóricos e práticos săo apresentados e alguns pontos fracos do STI revelados.
Palavras-chave: Acústica de salas , Acústica Arquitetônica , Inteligibilidade da fala , Índice de Transmissão da Fala , Técnicas de Medições em Acústica
ABSTRACT
Worldwide, the STI is gaining increased importance for the evaluation of intelligibility in public places. Often, the STI already is part of the requirements in the solicitation for the construction of a new building. If a minimum stipulated STI value cannot be reached after finishing the construction, the building contractor has to rectify the problem, otherwise he is held liable and subject to contractual penalties. For this reason, the STI is already simulated in the planning phase and later verified by measurements on site. This article tries to present the fundamental concepts of the STI and the techniques and signal processing to obtain it. Some theoretical and practical examples are shown and some weak points of the STI revealed.
Key-words: Room Acoustics , Architectural Acoustics , Speech Intelligibility , Speech Transmission Index , Measuring Techniques in Acoustics
1. Introduçăo
Obter uma qualidade acústica satisfatória e uma boa inteligibilidade da voz humana em lugares onde é primordial que um locutor seja ouvido e entendido por todas as pessoas presentes (por exemplo auditórios, salas de aulas, estádios, igrejas, aeroportos, ferroviárias, rodoviárias, etc.) sempre foi um assunto complicado. A situaçăo é pior no Brasil, devido ŕ sua condiçăo de país tropical, que reflete na maneira de construir. Para garantir uma boa ventilaçăo nos dias quentes de verăo, é comum deixar amplos văos na alvenaria, pelos quais o ar, mas infelizmente também o ruído, circula entre o exterior e interior do prédio. Os onipresentes aparelhos de ar condicionado causam um nível constante de ruído de fundo que atrapalha bastante o entendimento, como pôde ser experimentado no próprio auditório da faculdade de engenharia civil da Unicamp que sediou a segunda ediçăo do simpósio da AcMus na qual este trabalho foi apresentado.
Como as janelas brasileiras geralmente năo tęm projeto de vedaçăo contra o frio, elas săo de feitio simples e possuem molduras simples de alumínio para o deslizamento que também năo vedam efetivamente o barulho oriundo das ruas.
Para agravar a situaçăo, os níveis de ruído nas cidades brasileiras săo notavelmente acima dos encontrados nos países mais ricos, pela falta de controle e pela má conservaçăo de veículos e vias de circulaçăo. Recentemente, os ônibus municipais começaram a ser equipados com ar condicionado, cujo compressor no teto é uma indesejável fonte adicional de ruído.
Finalmente, também existe um fator cultural: Shows ao vivo, comícios, cultos evangélicos, anúncios por carros com caixas de som enormes no teto e até conversa nos botequins e restaurantes, tudo parecendo precisar de um nível de som exageradamente alto.
Enfrentamos entăo dois agravantes no Brasil: de um lado, um elevado ruído de fundo, e do outro, edificaçőes com pouco isolamento contra o ruído. Como terceiro agravante, tratamento acústico com absorvedores dentro dos prédios é coisa rara, devido aos custos, mas também como medida de proteçăo ŕ higiene e ŕ saúde pela facilidade que os materiais absorventes tęm em acumular sujeira e mofo devido ŕs altas temperaturas e taxas de umidade do ar.
Em lugares cuja funçăo principal é de passar informaçőes de forma oral de uma pessoa para um grupo de outras (escolas, universidades, auditórios), ou onde existe uma grande concentraçăo de pessoas que, num caso de emergęncia, precisam receber avisos inteligíveis mesmo se houver pânico e gritaria (estádios, aeroportos, salas de show), faz sentido de prescrever uma inteligibilidade mínima em todos os pontos do público.
A maneira mais certa de avaliar a qualidade da transmissăo de fala humana é de conduzir extensos testes de inteligibilidade com listas de palavras ou sílabas, envolvendo muitas pessoas espalhadas na área útil do lugar, e aplicar métodos de avaliaçăo estatística. No entanto, esse procedimento é muito moroso e năo permite a previsăo da inteligibilidade ainda na fase de planejamento de uma edificaçăo.
Dos múltiplos parâmetros acústicos objetivos que podem ser obtidos mediante simulaçăo e mediçăo da conjuntura acústica, o que mais se popularizou nas últimas tręs décadas e que finalmente foi introduzido em normas e regulamentos de vários países, é o STI (Speech Transmission Index). A razăo disso é que ele leva em consideraçăo tanto a reverberaçăo e os ecos das salas quanto o ruído de fundo, sendo portanto sensível aos dois maiores inimigos da inteligibilidade. Além disso, ao contrário de outros parâmetros acústicos conhecidos, o resultado é um simples índice, de fácil interpretaçăo, que ocupa valores entre 0 (fala completamente ininteligível) e 1 (ótima inteligibilidade).
2. História
Os dois idealizadores do STI, os holandeses Tammo Houtgast e Herman J.M. Steeneken, já se envolviam em testes de inteligibilidade no final dos anos 60. Na época, eles foram solicitados para pesquisar o alcance da transmissăo de rádios VHF. Os testes, conduzidos pelo método tradicional de avaliaçăo subjetiva, consumiram tempo considerável, o que incentivou os dois pesquisadores a desenvolver um método objetivo e bem mais rápido com base em sinais artificiais.
O resultado desse afă foi apresentado num artigo importante na revista Acustica, em 1971 (depois que o manuscrito foi refutado pela JASA!), seguido por inúmeras outras publicaçőes da dupla, nas quais eles foram apresentando aperfeiçoamentos e verificaçőes do método. O STI, junto com o RASTI (Rapid STI), que é uma simplificaçăo para cálculo mais rápido que hoje está caindo em desuso, culminou na norma IEC 268-16 em 1988. A segunda ediçăo dessa norma entrou em vigor em 1998 e foi substituída em 2003 pela atual versăo, a IEC 60268-16. Essa terceira ediçăo introduziu duas versőes do STI, uma direcionada para fala feminina e a outra para fala masculina, e leva em conta a redundância de resultados parciais em bandas de oitava adjacentes. Uma quarta ediçăo está em fase de produçăo e deverá considerar outros aspectos práticos que ocorrem em situaçőes típicas de mediçăo. Também tentará resolver algumas ambigüidades e pontos mal-esclarecidos.
A descriçăo da obtençăo do STI neste artigo se baseia na versăo vigente, ou seja, na terceira ediçăo de 2003 [1].
3. Conceito Básico
No início dos trabalhos, Steeneken e Houtgast [2-5] encetaram uma série de ensaios para avaliar propriedades estatísticas da fala humana e para descobrir quais dessas propriedades săo sensíveis a mudanças em termos de inteligibilidade. Eles descobriram que a intensidade, ou seja, o quadrado do sinal temporal da voz, exibe componentes espectrais significativos na faixa de 0.5 a 25 Hz, com um valor máximo localizado na regiăo entre 3 e 4 Hz.
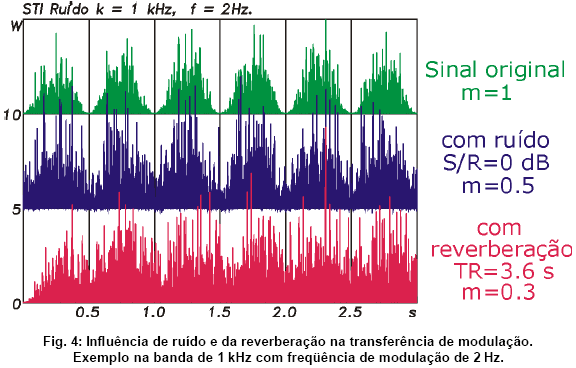
Num ambiente com ruído de fundo ou reverberaçăo notável, é claro que os mínimos da intensidade (as lacunas entre palavras e sílabas) săo preenchidos, o que leva a uma aparente reduçăo da profundidade da modulaçăo da intensidade. No caso de ruído de fundo, esse preenchimento independe da freqüęncia de modulaçăo. Já no caso de reverberaçăo, flutuaçőes rápidas da intensidade sofrem mais nivelamento do que trechos com freqüęncia de modulaçăo lenta, onde a reverberaçăo já decai bastante dentro do intervalo entre dois máximos da modulaçăo.
Esses fatos levaram ŕ concepçăo da funçăo de transferęncia de modulaçăo, ou modulation transfer function (MTF) em inglęs. A MTF representa a transferęncia m(f) do envelope da intensidade da entrada ŕ saída, dependendo da freqüęncia f de modulaçăo. O ruído age como um atenuador na MTF, enquanto que a reverberaçăo exibe o efeito de um filtro passa-baixa.
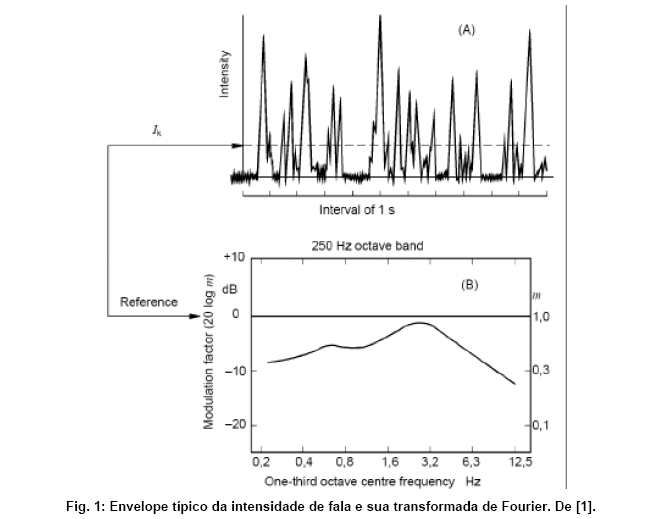{kind=link}
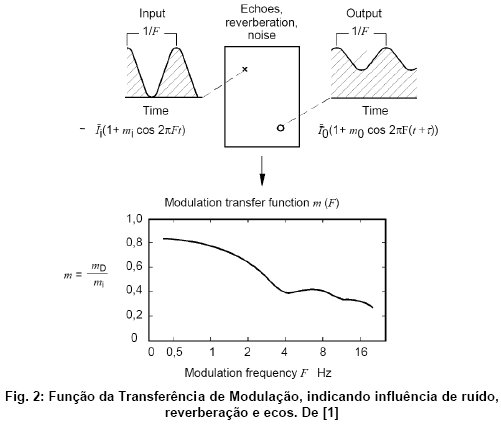
Para medir a MTF, a forma original do STI estipula a modulaçăo senoidal da intensidade (ou seja, do quadrado) de um sinal de ruído. Isso corresponde ŕ multiplicaçăo do ruído com o termo v{1+cos (2p fM t)}, sendo fM a freqüęncia da modulaçăo. Para poder ponderar várias faixas com importância variada para a transmissăo da voz humana, o ruído é dissecado nas 7 oitavas entre 125 Hz e 8 kHz mediante passa-faixas. Cada um desses 7 ruídos filtrados, por sua vez, é modulado por 14 freqüęncias, subindo em passos de terços de oitavas de 0.63 Hz até 12.5 Hz. Ao todo, săo entăo 98 sinais diferentes, e cada um deles é reproduzido e capturado separadamente no ambiente sob investigaçăo.
3.1 Cálculo dos valores mk,f
No ponto de recepçăo, o fator de reduçăo da modulaçăo m para cada um desses 98 sinais é avaliado da seguinte maneira:
1) Aplicar um filtro de oitava (que corresponde ŕquele utilizado na filtragem do ruído),
2) elevar o sinal filtrado ao quadrado,
3) aplicar ao sinal filtrado e elevado ao quadrado uma transformada discreta de Fourier de uma freqüęncia só, isto é, a da modulaçăo. Em outras palavras, multiplicar o intervalo analisado com o seno e o coseno da freqüęncia de modulaçăo,
4) dividir o módulo do resultado da análise de Fourier, ou seja v{Re2+Im2}, pela energia total, quer dizer, a soma da intensidade no intervalo analisado,
5) e finalmente multiplicar esse resultado com 2.
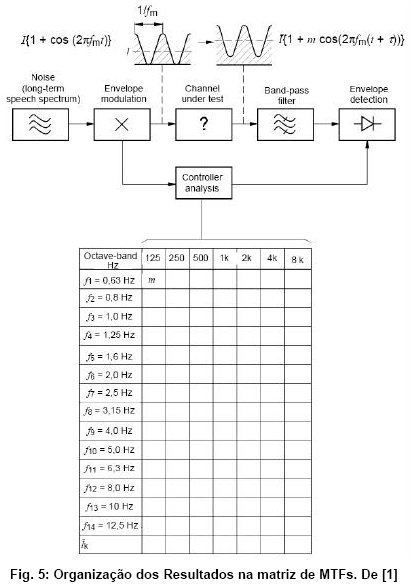
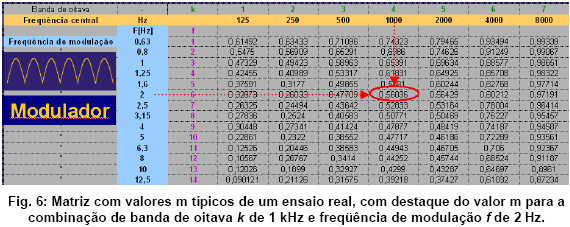
Os 98 resultados diferentes săo organizados na chamada matriz de MTF, uma tabela com as freqüęncias de modulaçăo agrupadas nas linhas e as freqüęncias centrais do ruído filtrado nas colunas. Essa matriz serve como base para o cálculo do próprio STI, apresentado no capítulo 5. Mas vamos primeiro conhecer um método bem mais rápido para chegar ŕ matriz dos valores m(f):
4. Avaliaçăo rápida dos valores m(f) mediante resposta impulsiva
O método tradicional, que consiste em tocar e analisar cada uma das 98 combinaçőes de ruído modulado, é muito moroso, consumindo no mínimo 15 minutos. Isso o restringe aos casos nos quais meramente uma comunicaçăo ponto a ponto esta sendo investigada (por exemplo, sistemas de comunicaçăo com headset, como os utilizados pelos pilotos de aviőes).
Para a avaliaçăo do STI em áreas com cobertura para muitas pessoas, é imprescindível medir o STI em vários pontos a fim de poder executar médias espaciais. Nesse caso, a duraçăo de cada avaliaçăo do STI completo é proibitiva. Uma primeira tentativa de diminuir o tempo total seria de tocar ruído simultâneo em todas as bandas. Como o primeiro passo no ponto de recepçăo é o de isolar cada banda com filtros de oitavas, é possível obter 7 valores m concomitantemente, contanto que a seletividade dos passa-faixas seja suficiente. Uma derivada do STI concebida especialmente para a avaliaçăo da inteligibilidade de sistemas de sonorizaçăo, o STIPA (STI para PAs, PA = Public Address), vai a um passo além: Ela só utiliza seis bandas de ruído, das quais cada uma é modulada com duas freqüęncias (relaçăo 1:5). Cada uma das duas só chega a uma profundidade de modulaçăo de m = 0.55, ao contrário do m = 1 no método tradicional. Todas as bandas săo tocadas simultaneamente, o que reduz o tempo de mediçăo e avaliaçăo a algo em torno de tipicamente 12 segundos. Porém, como o método só explora duas freqüęncias de modulaçăo em cada banda, ele é menos preciso do que o método tradicional e em alguns casos específicos pode errar bastante na prediçăo da inteligibilidade.
Por isso, é sempre recomendável medir o STI completo. Em vez do ruído modulado reproduzido seqüencialmente, existe um método bem mais rápido para chegar a todos os valores m da matriz. Ele explora as respostas impulsivas (RIs) do ambiente pesquisado. Segundo a teoria, a RI entre dois pontos descreve todas as características lineares do caminho de transmissăo. De certa forma, todas as informaçőes sobre reflexőes e reverberaçăo devem entăo estar embutidas nela. De fato, a avaliaçăo dos valores de transferęncia m a partir de RIs funciona de forma muito parecida ŕ dos ruídos modulados:
1) Aplicar um banco de 7 filtros de oitava, de 125 Hz até 8 kHz, ŕ RI de banda larga. Os filtros devem cumprir a norma IEC 1260. Filtros passa-faixa de ordem 6 a 8, do tipo Butterworth, ou melhor Chebychev com baixo ripple, servem para o propósito.
2) Elevar os sete sinais resultantes ao quadrado,
3) Aplicar a cada um dos 7 sinais filtrados e elevados ao quadrado uma transformada discreta de Fourier com as 14 freqüęncias exatas (entre 0.63 Hz e 12.5 Hz) de modulaçăo estipuladas pela norma do STI. Mais uma vez, isso significa multiplicar o intervalo analisado com o seno e o coseno de cada freqüęncia de modulaçăo, o que resulta em 14 partes reais e imaginárias para cada banda de oitava. Para evitar erros de vazamento, só um número inteiro de períodos deverá ser analisado para cada freqüęncia de modulaçăo. Como a freqüęncia mais baixa de modulaçăo é de 0.63 Hz, isso também significa que as RIs medidas devem acolher no mínimo um período inteiro dessa freqüęncia, ou seja, o comprimento da RI năo deve ser inferior a 1.6 segundos. Caso contrário, erros no cálculo dos valores m para as freqüęncias baixas de modulaçăo săo inevitáveis. Em ambientes com muita reverberaçăo, é claro, o comprimento da RI deve ser maior ainda para năo cortar partes significantes da cauda reverberante, o que levaria a uma superestimaçăo do STI. Alternativamente, uma FFT pode ser aplicada sobre todo o intervalo e os valores nas freqüęncias exatas de modulaçăo podem ser obtidos por interpolaçăo entre os valores vizinhos do espectro FFT. Mas como săo poucas as freqüęncias avaliadas, a FFT năo é o cálculo mais eficiente nesse caso. Além disso, a interpolaçăo e a falta da possibilidade de restringir a analise a intervalos inteiros das freqüęncias exatas de modulaçăo tornam esse método menos preciso.
4) Finalmente, dividir o módulo dos 14 resultados da análise de Fourier em cada banda, ou seja v{Re2+Im2}, pela energia total dessa banda (a parte DC), o que resulta diretamente nos 14 valores m de cada banda.
Tudo isso significa que uma RI só, que na maioria das vezes é levantada de qualquer maneira para avaliar outros parâmetros acústicos (sobretudo os tempos de reverberaçăo), é suficiente para chegar rapidamente aos 98 valores m que compőem a matriz das MTF.
Porém, existe uma grande diferença em relaçăo ao método tradicional. O intuito na captaçăo de RIs normalmente é de diminuir ao máximo a influęncia do ruído de fundo, para năo atrapalhar o cálculo dos tempos de reverberaçăo e demais parâmetros acústicos. Para chegar a essa meta, o sinal de excitaçăo normalmente é reproduzido com volume alto, e médias síncronas podem ser efetuadas para melhorar ainda mais a relaçăo S/R. Isso significa que a matriz dos valores m e o próprio STI obtidos a partir da RI săo praticamente isentos da influęncia do ruído de fundo. Para incluir ele devidamente neste noiseless STI, existem dois métodos. O primeiro é de utilizar como sinal de excitaçăo um ruído pseudo-aleatório (por exemplo, MLS) e pré-filtrar ele com um filtro de fala (speech filter) a fim de obter uma distribuiçăo espectral que corresponde ŕ da fala humana. Esse sinal deve ser tocado com o mesmo valor RMS ao que seria emitido por um locutor numa situaçăo típica de anúncio no ambiente pesquisado. Médias năo devem ser feitas. O resultado será que o ruído de fundo se espalhará com a proporçăo certa na RI e conseqüentemente terá reflexo correto na diminuiçăo do STI.
Ainda assim, esse método é pouco prático e pouco recomendável. As RIs captadas dessa maneira normalmente năo poderăo mais ser utilizadas para a avaliaçăo dos outros parâmetros acústicos (a năo ser que o ruído de fundo seja muito baixo, mas neste caso, o procedimento descrito seria desnecessário de qualquer maneira). Uma soluçăo muito melhor é medir separadamente o nível R do ruído de fundo e também o nível S+R de uma pessoa falando com volume típico no ambiente examinado. Ambos os níveis săo levantados nas bandas de oitavas entre 125 Hz e 8 kHz. O nível do orador é calculado através do L10 ou L12 (nível de pressăo sonora que está sendo ultrapassado em 10% ou 12% do tempo, respectivamente), ou através do valor RMS da fala, desconsiderando as folgas entre as sílabas. Quando a mediçăo do nível do orador no lugar examinado também inclui o ruído R de fundo, esse tem que ser excluído para chegar-se ao valor real do nível S do orador:
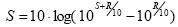
A relaçăo S/R servirá para manipular todos os 14 valores m de uma banda de oitava k por um termo de correçăo que será apresentado no capítulo 6.
Esse procedimento, além de ser mais prático e de execuçăo mais fácil, traz uma grande vantagem: A possibilidade de discernir o efeito do ruído de fundo e o da acústica da sala, prevendo a influęncia no STI quando só um dos dois varia.
5. Filtragem rápida das respostas impulsivas
Embora o cálculo descrito acima possa ser efetuado em tempo razoável em computadores modernos com velocidade de processamento na casa dos GHz, é possível apressar ele ainda mais a fim de obter os resultados finais quase instantaneamente, mesmo analisando RIs extensas ou de vários pontos de recepçăo em conjunto.
Uma maneira eficiente de reduzir o custo computacional é realizando reduçőes sucessivas da taxa de amostragem (downsampling) durante a filtragem em bandas de oitava. Após a aplicaçăo do passa-baixa que define o limite superior de cada banda de oitava, a taxa de amostragem pode ser diminuída em passos de 2 (quer dizer, cada segundo valor do sinal é simplesmente descartado), observando um limite razoável de aliasing (componentes espelhados) que possa entrar no resultado. Um critério razoável é garantir que a nova taxa de amostragem fique no mínimo 3 a 4 vezes acima da freqüęncia de corte do passa-baixa.
Após a elevaçăo ao quadrado, outro downsampling substancial pode ser efetuado, uma vez que a análise dos componentes espectrais das RIs filtradas e quadradas se estende meramente até 12.5 Hz. Portanto, a freqüęncia final de amostragem pode ser reduzida para algo em torno de 100 a 300 Hz. Nesse caso, o cálculo das transformadas discretas de Fourier é concluído tăo rapidamente que a contribuiçăo ao tempo total do cálculo do STI é negligenciável. Levando isso em consideraçăo, um passa-baixa de ordem baixa (2 a 4) pode ser utilizado para filtrar os sinais elevados ao quadrado antes de reduzir a taxa de amostragem deles ao valor final. Manter ela 10 ou 20 vezes acima da maior freqüęncia considerada (12.5 Hz) garante que o efeito de componentes aliasing seja desprezível, năo obstante a inclinaçăo branda de um passa-baixa de ordem tăo baixa.
Essas consideraçőes levam ao processamento da RI de banda larga apresentado na Fig. 7. Ele procede da banda de oitava mais alta (8 kHz) até a banda mais baixa (125 Hz). Em cada ciclo, a RI é primeiramente tratada com um passa-baixa com freqüęncia de corte de v2 fm (fm = freqüęncia nominal da banda). Em seguida, a taxa de amostragem é reduzida para a metade e o resultado é guardado num campo temporário (“workfield” na Fig. 7). Depois disso, um passa-alta com freqüęncia de corte de fm/v2 é aplicado. A saída desse filtro é elevada ao quadrado e filtrada com outro passa-baixa de ordem 4 e freqüęncia de corte de 40 Hz. Finalmente, a taxa de amostragem desse sinal é diminuída para o valor final. Isso o deixa pronto para ser submetido ŕ análise de Fourier, resultando nos 98 valores m k,f.
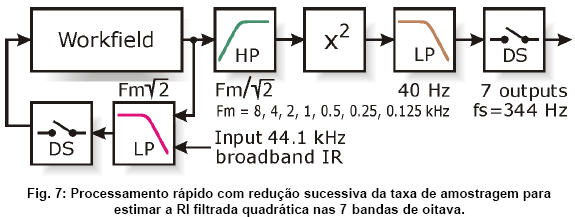
O ganho computacional é considerável: Num PC equipado com P4 de 2.4 GHz, o cálculo do STI a partir de uma RI de 6 segundos (freqüęncia de amostragem: 44.1 kHz) é completado em menos de 200 ms.
6. Cálculo do STI a partir dos valores m
Os 98 valores m k,f constituem a base de cálculo do STI. Mas eles ainda sofrerăo algumas correçőes e transformaçőes antes de entrar na equaçăo final.
A primeira e mais importante correçăo, já anunciada no capítulo 4, é a que introduz a relaçăo S/R, contanto que os valores m tenham sido derivados devidamente de uma RI com influęncia desprezível do ruído:
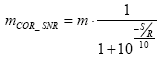
Desde a terceira ediçăo da norma IEC 60268-16, existem mais duas correçőes em bandas de oitavas que dizem respeito ao mascaramento em bandas adjacentes, e ao nível absoluto da fala do locutor, respectivamente. Ambas as correçőes săo modeladas como um ruído adicional que piora a transferęncia de modulaçăo, ou seja, baixa os valores m.
6.1 Consideraçăo do mascaramento e do limiar de audiçăo
O mascaramento diz respeito ao efeito psicoacústico de sobreposiçăo de um som forte sobre um som fraco numa freqüęncia vizinha. No caso do cálculo do STI, que trabalha com bandas de oitava, o mascaramento terá efeito notável se uma banda possuir um nível S da fala bem mais baixo do que nas bandas adjacentes (o que pode acontecer em sistemas eletro-acústicos mal equalizados, por exemplo). Para simplificar o cálculo, só a banda inferior é considerada. O mascaramento dessa banda k-1 sobre a banda k é modelada como uma linha que decai com uma declinaçăo fixa em dB/oitava:
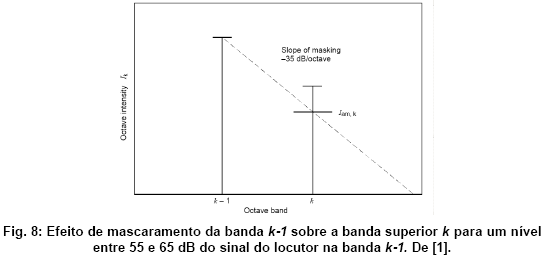
Para complicar um pouco as coisas, a inclinaçăo dessa reta depende do nível Sk-1 na banda k-1. Na norma, essa dependęncia é tabelada em passos discretos de 10 dB:

Felizmente, a inclinaçăo pelo menos năo depende da freqüęncia. A influęncia do mascaramento é modelada como uma intensidade de som que interfere na banda k e entrará no termo de correçăo dos valores m:
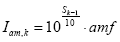
Iam,k é o mascaramento exercido na banda k, Sk-1 é o nível do mascarador na banda inferior k-1, e amf é o fator de mascaramento dependendo desse nível Sk-1 e determinado com a ajuda da Tabela 1.
Quanto mais o nível de fala cair e se aproximar do limiar de audiçăo, maior terá que ser a relaçăo S/R para manter a mesma inteligibilidade. Para dar conta desse efeito, um terceiro componente, o limiar absoluto de recepçăo (absolute reception threshold) entra no termo de correçăo dos valores m. Esse limiar depende da freqüęncia. Os valores em dB podem ser encontrados na Tabela 2. Para o cálculo, eles săo transformados para intensidades:
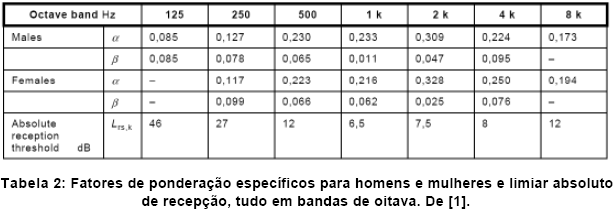{kind=link}
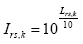
Finalmente, com a ajuda da própria intensidade Ik da fala na banda k,
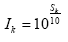
o termo de correçăo mcork, incluindo também a influęncia da relaçăo S/R, se torna:
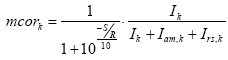
Todos os 14 valores m k,f de determinada banda k agora podem ser multiplicados com esse termo de correçăo:
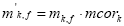
Resta ressaltar que as duas correçőes relativas ao limiar absoluto de audiçăo e ao mascaramento só tęm efeito significativo se o nível de fala for baixo e divergir muito em bandas adjacentes, respectivamente.
6.4 Cálculo dos índices de transmissăo e médias finais
Após esse ajuste dos valores m, o STI pode ser calculado. Como primeiro passo, cada valor m é transformado em uma relaçăo sinal/ruído (signal to noise ratio, SNR) aparente:
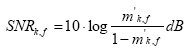
Se a reduçăo da transferęncia de modulaçăo fosse exclusivamente ocasionada pelo ruído de fundo, esse valor SNR de fato apresentaria a relaçăo sinal/ruído real.
Todos os 98 valores SNR săo ceifados a uma faixa de ±15 dB. Quer dizer, um valor muito bom que ultrapassa 15 dB é fixado em 15 dB, e um valor péssimo que cai abaixo de -15 dB é ajustado em -15 dB.
Em seguida, cada um dos valores SNRk,f engastado na faixa de ±15 dB é transformado no chamado índice de transmissăo (transmission index, TI):
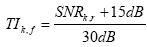
Devido ŕ ceifa anterior dos valores SNRk,f, os TIk,f só podem tomar valores entre 0 e 1. Portanto, eles já se assemelham com o STI final, e de fato este é calculado em duas etapas como média sobre todos os 98 índices de transmissăo. A primeira etapa é uma simples média aritmética dos 14 índices dentro de cada banda de oitava:
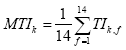
Este índice de transmissăo de modulaçăo (Modulation transfer index, MTIk) por oitava entăo dá igual peso a todas as 14 freqüęncias de modulaçăo na faixa de 0.63 Hz a 12.5 Hz considerada pelo STI. Mas existem propostas para ponderar mais a faixa entre 2 e 6.3 Hz, que tem maior importância para a inteligibilidade [9].
Finalmente, os 7 valores MTIk formam o STI através da seguinte somaçăo ponderada:
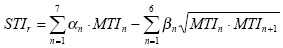
A parte essencial é a primeira soma, que calcula a média dos MTIK, mas nesta etapa năo dando igual importância a todos os componentes do somatório. A segunda soma é um termo de redundância só introduzido a partir da terceira versăo da norma IEC 60268-16. Ela considera que um resultado bom em uma banda pode parcialmente compensar um resultado pior numa banda adjacente. Os fatores de ponderaçăo a e ß, específicos para cada banda de oitava, dependem do sexo do locutor, o que é outra novidade da terceira ediçăo da norma:
A banda mais baixa, 125 Hz, nem é considerada para mulheres, cuja voz normalmente tem fundamental só a partir de 150 Hz. Para os dois sexos, pesos maiores săo dados nas oitavas entre 500 Hz e 4 Hz.
O pequeno índice r na sigla STIr significa “revised” (revisado) e indica que as devidas correçőes do fator m foram aplicadas. Indica igualmente que o termo de redundância foi utilizado na somaçăo final, junto com os novos coeficientes separados para mulher e homem.
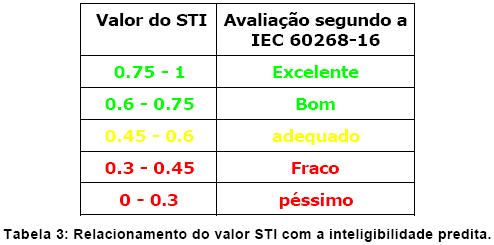
7. Avaliaçăo do valor do STI
8. Deduçăo de outras medidas de inteligibilidade
Duas outras medidas correntes para descrever a inteligibilidade podem ser extraídas do STI mediante equaçőes simples. Trata-se do valor da Common Intelligibility Scale, CIS:
CIS =1+ log( STI ), 0 <= CIS <=1
e do índice de articulaçăo %AlCons, que é calculado através de uma equaçăo empírica segundo Farell-Becker:
%AlCons =170.5405 · e-5.419×STI , 0 <=%AlCons <=100
9. Mecanismos básicos que influenciam no STI
Neste capítulo, iremos conhecer alguns casos teóricos e os efeitos que eles exercem sobre o STI. Para simplificar o panorama, as correçőes que dizem respeito ao mascaramento e ao limiar absoluto foram deixados fora do cálculo.
9.1 Influęncia de ruído
Ruído estacionário exerce uma influęncia na MTF que independe da freqüęncia de modulaçăo. A influęncia pode ser diretamente calculada através da equaçăo já conhecida:
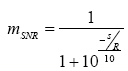
Uma relaçăo S/R de –15 dB ou pior em todas as bandas significa que o STI fica no patamar do “pior possível”, ou seja, 0. A partir desse limiar, cada aumento de 3 dB na relaçăo S/R faz com que o STI aumente em 0.1, até finalmente chegar ao valor 1 (indicando inteligibilidade perfeita) quando a relaçăo S/R atinge e ultrapassa 15 dB.
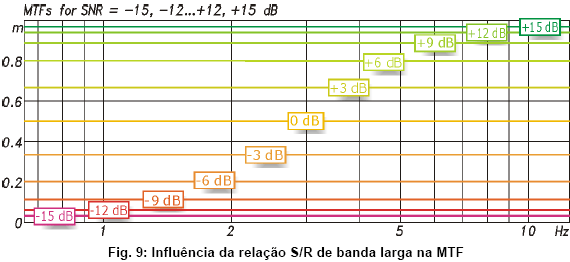

Esse relacionamento se deve ŕ projeçăo linear da relaçăo S/R ŕ faixa dos índices de transmissăo entre 0 e 1: TI = (S/R + 30 dB) / 15 dB.
Outro fato interessante é que uma relaçăo S/R de 0 dB em todas as bandas de oitava resulta num STI de exatamente 0.5, perto da divisa entre “adequado” e “fraco”.
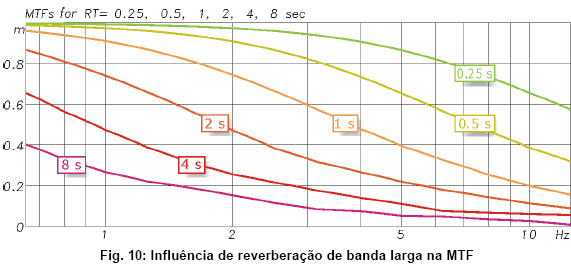
9.2 Influęncia de reverberaçăo
Como já mencionado, reverberaçăo surte um efeito passa-baixa na MTF. Quer dizer, afeta bastante as altas freqüęncias de modulaçăo, enquanto tem efeito mais brando nas baixas. Contanto que o decaimento seja estritamente exponencial, indicando condiçőes perfeitas de campo difuso, a influęncia de reverberaçăo na MTF pode ser expressa pela seguinte equaçăo:
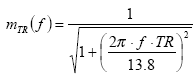
Com um tempo de reverberaçăo TR de 1 segundo em todas as bandas, o STI atingiria meramente um valor de 0.59, o que significa que ele já sairia da categoria “boa” para a “adequada”. Com 2 segundos de TR, o STI cairia para 0.44, o que já corresponde ŕ categoria “fraco”. Na praxe, os tempos de reverberaçăo raramente săo iguais em todas as bandas de oitava. Tendem ser mais altos nas bandas baixas e mais bem comportados nas médias e nas altas. As bandas com maior ponderaçăo no cálculo do STI săo as de 500 Hz até 4 kHz.

9.3 Influęncia de um eco
Ecos causam um efeito “filtro de pente” na MTF. Isso se deve ŕ interferęncia construtiva e destrutiva da adiçăo com o som direito causando “batimento”. A influęncia de um eco de banda larga com nível variável também pode ser calculada por uma equaçăo:
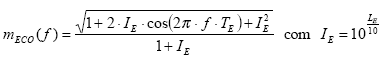
O exemplo escolhido aqui trata com um eco de banda larga que chega 100 ms após o som direto. A Tabela 6 indica que mesmo se chegar com nível igual ao do som direto, o STI sofrerá queda para apenas 0.68, no meio da faixa de avaliaçăo “bom”.
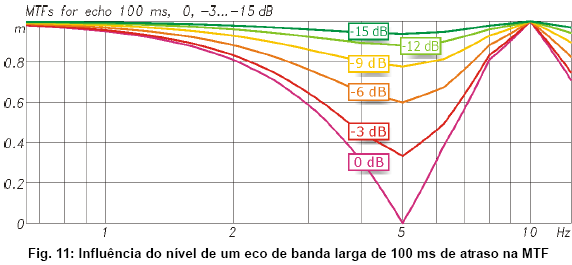
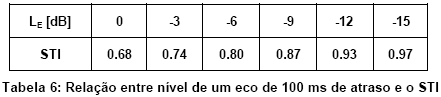
No entanto, esse tipo de eco prejudica bastante o entendimento, enquanto o STI năo acusa suficientemente a perda de inteligibilidade. Essa insensibilidade a ecos tardios e nocivos ŕ inteligibilidade é um ponto fraco do STI, que será corroborado com um exemplo prático no capítulo 10.3.
10. Algumas mediçőes reais do STI
Vamos agora pôr as măos na massa e conhecer algumas mediçőes reais para nos familiarizar com o STI. Mais uma vez, as correçőes referentes ao mascaramento e ao limiar de audiçăo năo foram aplicadas, mas de qualquer maneira, elas surtem pouquíssimo efeito (uma piora de cerca 0.02) no resultado final.
10.1 Centro cultural em Düsseldorf
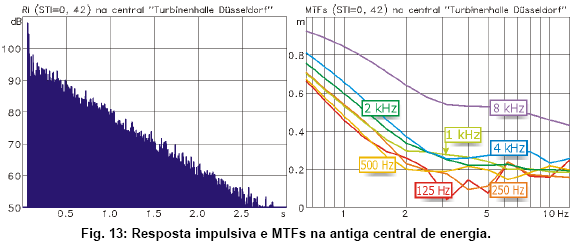
O primeiro exemplo é uma antiga central de energia na cidade de Düsseldorf, Alemanha, que foi transformada num centro cultural pela prefeitura.

As mediçőes foram feitas com as obras de alvenaria já concluídas, mas ainda sem o revestimento de material absorvente. Os ensaios tiveram exatamente o propósito de predizer qual a área que devia ser coberta com material absorvente para chegar a tempos de reverberaçăo e STI razoáveis e compatíveis com o uso multi-funcional da sala.
A mediçăo revelou que o tempo de reverberaçăo da sala vazia era de 3.5 segundos. O STI, com um valor de 0.42, também indica condiçőes complicadas. Ainda assim, uma auralizaçăo (convoluçăo da RI com fala seca) mostrou que apesar da reverberaçăo fortíssima, ainda foi possível entender o locutor (que fala de maneira bastante pausada na gravaçăo utilizada). O motivo disso é que o som direto, junto com uma primeira reflexăo benéfica ocorrendo 10 ms depois, sobrepuja em 10 dB a reverberaçăo (que demonstra um decaimento quase idealmente exponencial) que se estabelece depois. Isso faz toda a diferença, pois o nosso sentido de audiçăo tem capacidade excelente de discernir a primeira chegada de som dos componentes atrasados.
10.2 Estádio Olympia em Berlim
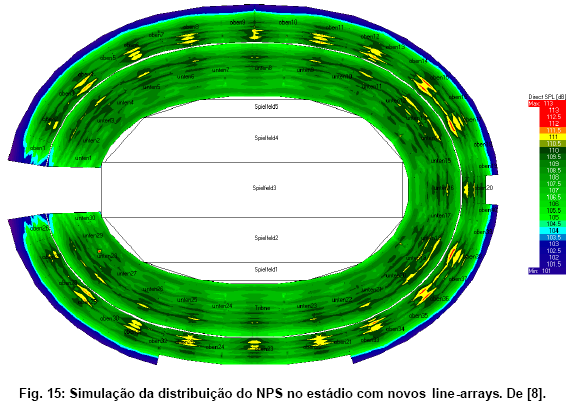
O segundo exemplo é o estádio olímpico em Berlim que foi um dos utilizados na copa do mundo de 2006, inclusive para o jogo final entre França e Itália. No ano anterior, foi realizada uma reforma abrangente, incluindo um novo sistema de sonorizaçăo, composto por linearrays, como de costume atualmente.
O primeiro passo em projetos desse tamanho normalmente é utilizar um software de prediçăo da distribuiçăo do som. Com os dados de direcionalidade e potęncia máxima dos alto-falantes e o modelo do recinto a ser sonorizado, esses softwares săo capazes de calcular mapas com níveis na área de cobertura e até predizer o STI (com base no som direto, um número reduzido de primeiras reflexőes e na reverberaçăo calculada com meios estatísticos). Executar essa simulaçăo é um passo indispensável para verificar a adequaçăo dos alto-falantes escolhidos. Nesse caso, a análise também foi exigida na licitaçăo.
Após a instalaçăo do sistema de sonorizaçăo, coube verificar se os valores de STI e o nível máximo preditos foram cumpridos. A uniformidade da resposta em freqüęncia (pré-requisito: ±3 dB na faixa 70 Hz – 15 kHz) também foi investigada. Para verificar essas metas de formarepresentativa, nada menos que 200 mediçőes de RIs foram executadas em pontos espalhados sobre toda a área do público no estádio vazio. Em termos de acústica de sala, essa situaçăo apresenta o pior caso, com a maior reverberaçăo possível. Para levar o efeito absorvedor do público em consideraçăo, um “bônus” conservador de 0.05 (calculado a partir da reverberaçăo medida sem público e estimada com público) foi concedido ao valor final do STI.

Antes disso, a relaçăo S/R foi modelada com base no nível S máximo alcançado pelo sistema de sonorizaçăo, predito pela simulaçăo e verificado posteriormente com ruído rosa. Junto com um ruído R médio de 92 dB(A) estipulado para o público - em situaçőes extremas, como a exaltaçăo após um gol, esse pode chegar até 110 dB(A) -, chegou-se a um valor de 13 dB para a relaçăo S/R, correspondendo a um fator de reduçăo de 0.95 para todos os valores m da matriz das MTFs.
Para a amostra de RI apresentada na Fig. 16, essa correçăo S/R diminuiu o STI de 0.58 para 0.55, enquanto o bônus acrescentado resultou num valor final de 0.6, na fronteira entre as categorias “adequado” e “bom”. O pré-requisito estipulado pelo mandante da obra era um STI mínimo de 0.5 a ser cumprido em no mínimo 90% dos assentos no estádio lotado.
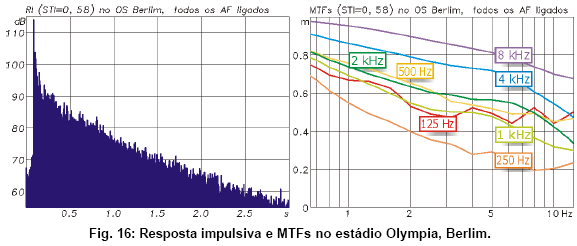
A reverberaçăo no estádio vazio é enorme: 5 segundos na faixa entre 500 Hz e 2 kHz. Mesmo assim, com as devidas correçőes, o STI dá “luz verde” neste exemplo. Mais importante: A convoluçăo da RI com fala seca revela que tudo pode ser entendido sem maiores problemas, năo obstante a cauda reverberante maciça que acompanha cada sílaba. A razăo disso mais uma vez é a boa relaçăo do som direto sobre a reverberaçăo difusa. Como pode ser visto na Fig. 16, o som direto chega aos ouvintes do público com nível quase 20 dB acima da cauda reverberante. Isso é essencialmente fruto do uso de line-arrays, que agem como fonte de linha, emitindo ondas quase cilíndricas. Ao contrário de fontes pontuais, fontes de linha tęm perda de somente 3 dB com cada dobro da distância, reforçando o som direto particularmente nas áreas mais afastadas dos alto-falantes.
Muitas tarefas de sonorizaçăo contam com esse problema: Nada ou pouca coisa pode ser feita para mudar uma acústica difícil que um recinto possa ter. A soluçăo entăo é otimizar a radiaçăo dos alto-falantes, buscando cobertura homogęnea só na área do público com emissăo de ondas coerentes.
10.3 Hangar de dirigíveis perto de Berlim
O terceiro exemplo foge um pouco do escopo de lugares comuns a serem sonorizados. Tratase de um hangar gigante que foi erguido a 80 km de Berlim para abrigar a construçăo de dirigíveis para transporte de cargas. A empresa faliu e o hangar agora abriga um parque temático tropical (bom, pelo menos năo virou templo evangélico).
As mediçőes foram feitas na fase da transiçăo do destino da edificaçăo enorme, com comprimento de 360 m, largura de 240 m e uma cúpula cujo pé-direito atinge 107 m no centro.

A RI mostra uma cornucópia de reflexőes chegando centenas de milissegundos atrás do som direto, com intensidade bem maior do que ele. A forma côncava tanto das paredes quanto do teto surte um fortíssimo efeito focal que amplifica os ecos.
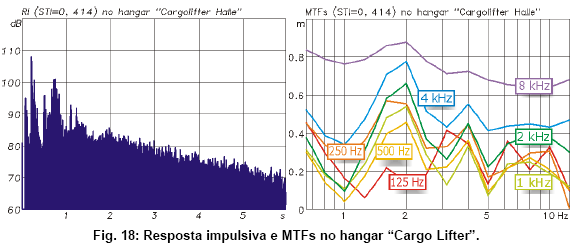
O STI calculado a partir dessa RI descomunal é de 0.414, praticamente o mesmo valor também calculado para o centro cultural vazio no primeiro exemplo. Isso podia nos levar a crer que embora tendo uma avaliaçăo “fraco”, ainda poderia ser possível entender algo nesse recinto. No entanto, testes de auralizaçăo com base nesta RI mostram que qualquer segmento de fala volta completamente embaralhado, com inteligibilidade praticamente nula. Esse é um bom exemplo para o fato que o STI trata reflexőes tardias e fortes de forma demasiadamente generosa, e năo leva suficientemente em conta a relaçăo do nível do som direto com elas.
11. Fraquezas do STI
Embora normalmente exiba uma correlaçăo boa com a inteligibilidade percebida, o STI pode errar bastante em casos extremos. O último exemplo é testemunha disso. De forma geral, o STI năo se importa de forma adequada com a estrutura temporal das respostas impulsivas. Por exemplo, um resultado idęntico para o valor de STI é obtido entre uma RI e a sua versăo invertida no eixo temporal, açăo que produz uma inteligibilidade desastrosa! Aparentemente, algumas propriedades do nosso senso auditivo, que aproveita componentes chegando no máximo 50 ms após o som direto, mas é despistado bastante por componentes chegando mais tarde, năo săo modeladas de forma psicoacusticamente correta no cálculo do STI.
Relacionado a esse aspecto é a percepçăo tridimensional do nosso ouvido, que ajuda bastante para discernir uma voz numa barafunda de outras vozes ou ruído em geral. Porém, o STI normalmente é levantado com a ajuda de um microfone onidirecional, desconsiderando as direçőes das quais os componentes da RI chegam ŕs orelhas do ouvinte e as diferenças interaurais. Por isso, seria mais adequado adquirir RIs binaurais com uma cabeça artificial [6]. Mas esse é um problema que também vale para a avaliaçăo dos demais parâmetros acústicos.
Outro ponto fraco do STI diz respeito ao equilíbrio tonal da transmissăo. Em ambientes onde a relaçăo S/R năo é problema, o STI pouco se importa como a resposta em freqüęncia de um sistema de sonorizaçăo. Um exemplo típico e com bastante relevância prática é a falta de agudos. No exemplo da Fig. 19, a funçăo de transferęncia medida no estádio em Berlim foi deliberadamente reduzida em até 25 dB a partir de 1 kHz.
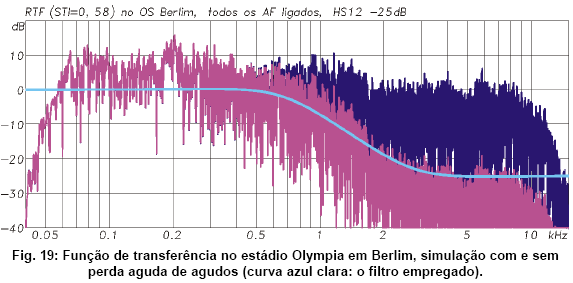
Como o nível năo tem influęncia nos componentes do STI que dizem respeito ŕ acústica de sala (reflexőes e reverberaçăo), os fatores m da matriz praticamente năo mudaram. Portanto, o valor final do STI (segundo a definiçăo original) também năo sofre alteraçőes. A correçăo do mascaramento introduzida na terceira ediçăo da norma só traz uma pequena queda do STI de 0.58 para 0.55. De maneira alguma acusa de forma adequada a perda quase total de inteligibilidade neste exemplo. E năo se trata de um caso puramente teórico. Ele pode acontecer de forma semelhante quando os tweeters do sistema de sonorizaçăo forem queimados. Como se vę neste exemplo, essa ocorręncia praticamente năo poderia ser detectada por uma mediçăo do STI.
O STI năo é somente destinado aos efeitos naturais de acústica de sala e ruído de fundo. Já pelas origens, quando os idealizadores visaram quantificar com meios objetivos a qualidade de transmissăo de rádios de comunicaçăo, ele sempre teve a pretensăo de também considerar corretamente qualquer influęncia técnica na transmissăo de som, seja ela deliberada ou năo. Porém, nem todos os efeitos de processamento e sonorizaçăo de fala tęm reflexo correto sobre o STI. Alguns até mudam o STI na direçăo errada.
O exemplo mais notável disso é o uso de compressores. Um compressor aumenta o nível nos trechos baixos de fala e diminui os picos. Isso tem duas conseqüęncias para o cálculo do STI. A primeira é que o método indireto, chegando ao STI através da RI, năo pode ser aplicado. As envoltórias dos sinais de excitaçăo tęm uma característica completamente diferente em comparaçăo ŕ fala, surtindo reaçőes do compressor igualmente diferentes. No caso de varreduras de seno, o compressor năo mudaria o ganho, pois o nível já se encontra em patamar constante (o negócio é diferente para compressores de multi-banda, é claro). Portanto, a inclusăo do compressor năo surtiria efeito nenhum. No caso de ruído pseudoaleatório (como MLS), muito sensível a quaisquer mudanças năo-lineares e/ou variáveis no tempo, o uso do compressor iria destroçar a RI, aumentando dramaticamente o ruído de fundo aparente.
Entăo, transmissőes de fala que passam por um compressor só podem ser investigadas com o método direto, quer dizer tocando seqüencialmente os 98 ruídos filtrados e modulados. Porém, como o compressor diminui os picos e levanta os vales, o que corresponde a uma diminuiçăo da profundidade de modulaçăo, o STI sofrerá uma queda notável, acusando uma perda de inteligibilidade. No entanto, o contrário é verdade: o compressor (empregado na medida certa) melhora a inteligibilidade e em casos críticos com muito ruído de fundo, pode elevar uma transmissăo do ininteligível até o razoável.
Uma coisa parecida acontece se frequency-shifters săo aplicados para suprimir realimentaçőes. O deslocamento linear de freqüęncia em torno de 5 ou 10 Hz năo prejudica a inteligibilidade, mas tem efeito bastante negativo no STI, pois as freqüęncias centrais de modulaçăo năo săo mais acertadas.
Existe uma série de diversos erros que podem acontecer em equipamentos eletro-acústicos que năo tęm efeito adequado no STI.
Um exemplo é o chamado center-clipping (ceifa central). Ele significa que o sinal, ao mudar a polaridade, desaparece completamente abaixo de um certo limite. Esse efeito pode ser ocasionado nos estágios complementares de amplificadores de potęncia se a corrente de repouso for baixa. Também pode se manifestar em conectores com mau contato e circuitos eletrônicos com defeito em geral. Como a intensidade do sinal já é baixa nos trechos que desaparecem, esse fenômeno muito desagradável tem pouquíssima influęncia no cálculo do STI. Todavia, prejudica bastante a inteligibilidade.
Outro exemplo é transmissăo intermitente, que pode acontecer em sistemas sem fio quando o sinal RF cair abaixo do limiar do squelch (supressor de ruído quando o canal está vazio), ou em sistemas digitais quando houver qualquer erro de transmissăo. Drop-outs na reproduçăo de fitas velhas, arquivos danificados, ou de streams de áudio através de uma conexăo digital compartilhada e temporariamente sobrecarregada săo outros exemplos corriqueiros dessa condiçăo desagradável. No entanto, esse tipo de estorvo também năo incomoda o STI. Uma simulaçăo típica é de periodicamente ligar e desligar o som, com silęncio de 100 ms em cada período. Esse estropício de fala a deixa quase completamente ininteligível. Por incrível que pareça, o STI aumenta ligeiramente nessa situaçăo!
Como se viu nos capítulos 4 a 6, o cálculo do STI é bastante complexo. Tendo em vista todas essas situaçőes nas quais o STI pode falhar, é justificável a dúvida se todo o esforço realmente valha a pena. Bradley [7] até mostrou que uma medida bem mais simples, o U50 (que é o useful-to-detrimental ratio, ou seja, a claridade C50 com influęncia do ruído de fundo), tem uma correlaçăo tăo boa com a inteligibilidade quanto o STI.
12. Conclusőes
O STI certamente năo é uma panacéia na análise e prediçăo da inteligibilidade em lugares padecendo ruído de fundo e acústica de sala carente, mas ele é bem prático e certamente um bom primeiro indicador de problemas que comprometem o entendimento. Embora possa falhar fatalmente em situaçőes extremas e um tanto atípicas, ele geralmente tem uma correlaçăo satisfatória com a inteligibilidade de fato experimentada no lugar pesquisado.
Uma pré-condiçăo para lugares que dependem da amplificaçăo da voz é que o sistema de sonorizaçăo funcione sem erros técnicos, sendo bem equalizado e livre de certos tipos de processamento (notavelmente dispositivos que mudam a dinâmica do sinal, tais como limitadores, compressores e gates). A resposta em freqüęncia sempre tem quer ser avaliada separadamente (mas podendo utilizar convenientemente as RIs já medidas para avaliar STI), porque o STI é insensível a desequilíbrio tonal.
O lado positivo do STI é que ele é uma ferramenta padronizada e amplamente utilizada mundialmente. Em casos litigiosos, ele pode desempatar um laudo técnico. Ao mesmo tempo, isso significa que ele tem que ser levantado cautelosamente, sempre visando excluir possíveis fontes de erros. A maior dela sem dúvida é a estipulaçăo da relaçăo S/R. O ruído depende muito da situaçăo e o nível do sinal também pode variar bastante entre locutores diferentes. Em contrapartida, o componente da acústica de sala pode ser traçado com boa precisăo, sobretudo se o sistema de sonorizaçăo a ser utilizado na reproduçăo da voz do locutor também for utilizado para medir as respostas impulsivas.
A avaliaçăo automatizada do STI por um equipamento năo substitui um especialista em acústica, muito pelo contrário. Com um pouco de experięncia, a matriz dos valores m (ou melhor, as MTFs) informam qual é a fonte predominante que compromete a inteligibilidade.
Cabe entăo a engenheiro tarimbado identificar a origem do problema e tirar ele pela raiz, se for factível.
13. Referęncias
[1] IEC 60268-16:2003, “Objective rating of speech intelligibility by speech transmission index”.
[2] Past, present and future of the Speech Transmission Index, TNO Human Factors, Soesterberg, Netherlands (ISBN 90-76702-02-0).
[3] TAMMO HOUTGAST, HERMAN J.M. STEENEKEN (1971), “Evaluation of Speech Transmission Channels by Using Artificial Signals”, Acústica 25, 355-367.
[4] HERMAN J.M. STEENEKEN, TAMMO HOUTGAST, “Basics of the STI measuring method”, available at http://www.steeneken.nl/sti.html
[5] HERMAN J.M. STEENEKEN, TAMMO HOUTGAST, “Improvements of STI: frequency weighing, gender, level dependent masking, and phoneme specific prediction” available at http://www.steeneken.nl/sti.html
[6] PETER MAPP, “Systematic & Common Errors in Sound System STI and Intelligibility Measurements”, 117th AES 2004 San Francisco, Preprint 6271.
[7] JOHN S. BRADLEY,” Optimising Sound Quality for Classrooms”, XX Encontro da SOBRAC, Rio de Janeiro, Outubro de 2002
[8] ANSELM GOERTZ, CHRISTIANE BANGERT, WOLFGANG AHNERT, STEFAN FEISTEL,” Setup and final measurements for a PA-System at the example of a large sports stadium in Berlin”, Tonmeistertagung Leipzig, Novembro de 2004, (infelizmente, só em alemăo)
[9] G. LEMBRUGGEN, A. STACEY, “Should the Matrix be reloaded?” Proceedings of the Institute of Acoustics, Vol. 25. Pt.8, 2003