
 Ā
Ā








 Article in PDF format
Article in PDF format How to cite this paper
How to cite this paperAn. 2. Seminßrio M·sica, CiĻncia e Tecnologia 2005
Ā
SĒntese Evolutiva de Segmentos Sonoros - SESS
Josķ Eduardo FornariI; J¶natas ManzolliI,II; Adolfo Maia Jr.I,III
IN·cleo Interdisciplinar de ComunicańŃo Sonora. Universidade Estadual de Campinas (UNICAMP). Rua da Reitoria, 165 - Cidade Universitßria "Zeferino Vaz". CEP: 13 091 - 970 - Caixa Postal: 6166 ¢ CAMPINAS - SP. fornari@nics.unicamp.br, jonatas@nics.unicamp.br, adolfo@nics.unicamp.br
IIDepartamento de M·sica ¢ Instituto de Artes.ĀUniversidade Estadual de Campinas (UNICAMP). Rua da Reitoria, 165 - Cidade Universitßria "Zeferino Vaz". CEP: 13 091 - 970 - Caixa Postal: 6166 ¢ CAMPINAS - SP. jonatas@nics.unicamp.br
IIIDepartamento de Matemßtica Aplicada ¢ IMECC.ĀUniversidade Estadual de Campinas (UNICAMP). Rua da Reitoria, 165 - Cidade Universitßria "Zeferino Vaz". CEP: 13 091 - 970 - Caixa Postal: 6166 ¢ CAMPINAS - SP. adolfo@nics.unicamp.br
RESUMO
A sĒntese evolutiva de segmentos sonoros (essynth) foi inicialmente apresentada em [Manzolli 2001]. Esta utiliza uma populańŃo de segmentos sonoros que evolui ao longo do tempo pela interańŃo de dois processos: reproduńŃo (composto por operadores genķticos) e seleńŃo (calculado pela distŌncia de Hausdorff). O som sintetizado ķ o caminho temporal da ĀevoluńŃo do melhor individuo da populańŃo. Este trabalho apresenta o primeiro modelo proposto da sĒntese evolutiva, onde os processos de reproduńŃo e seleńŃo sŃo feitos diretamente sobre o segmento sonoro. Resultados sonoros podem ser escutados em: http://www.nics.unicamp.br/~fornari/essynth1.
Palavras-chave: Acústica Musical , Acústica de Instrumentos Musicais , Síntese Sonora , Síntese Evolutiva
ABSTRACT
The Evolutionary Sound Synthesis method (essynth) was initially described in [Manzolli 2001]. It uses a Population set of waveforms that evolve in time by the interaction of two processes: reproduction (done by genetic operators)Ā and selection (done by the Hausdorff distance). The synthesized sound is the evolution path of best individuals in time. This paper presents the essynth's first model where the reproduction and selection processes are done directly on the waveforms . The sound results are available in audio, at: Āhttp:// www.nics.unicamp.br/~fornari/essynth1.
Key-words: Musical Acoustics , Acoustics of Musical Instruments , Sound Synthesis , Evolutive Synthesis
1. IntroduńŃo
A sĒntese evolutiva de segmentos sonoros (SESS) ķ um mķtodo que se baseia em princĒpios da ComputańŃo Evolutiva para gerańŃo de sons, conforme foi inicialmente proposta por [Manzolli, 2001]. Na SESS segmentos sonoros sŃo tratados como indivĒduos que pertencem exclusivamente a dois conjuntos. O primeiro ķ o conjunto chamado PopulańŃo que contĻm segmentos sonoros muito simples, tais como sons monof¶nicos senoidais, que irŃo evoluir ao longo do tempo, representado por gerań§es da populańŃo. O segundo conjunto ķ chamado de Alvo e contĻm segmentos mais complexos, tais como ruĒdo-branco. A evoluńŃo dos indivĒduos na populańŃo ķ guiada pelas caracterĒsticas dos indivĒduos do Alvo, assim este corresponde ao que seria a pressŃo condicionante do meio-ambiente na evoluńŃo de uma populańŃo biol¾gica. Neste cenßrio a evoluńŃo da populańŃo de sons ocorre no sentido de, a cada gerańŃo, ocorrerem sons mais complexos, a partir de sons inicialmente muito simples. A gerańŃo sonora na sĒntese evolutiva ķ feita por dois processos independentes: SeleńŃo, que seleciona o melhor indivĒduo de cada gerańŃo da populańŃo e ReproduńŃo, que cria novos indivĒduos na populańŃo. ╔ importante ressaltar que o caminho trańado em cada processo de sĒntese evolutiva ķ ·nico (nunca se repete) ainda que tenda a convergir para uma similaridade perceptual sonora. Dessa forma o mķtodo de sĒntese aqui apresentado tem o diferencial, em relańŃo Ós outras formas de sĒntese sonora, de nŃo ser determinĒstica, mas evolutivo.
2. O Mķtodo da SĒntese Evolutiva de Segmentos Sonoros
O mķtodo da SESS pode ser visto na figura abaixo (Figura 1).
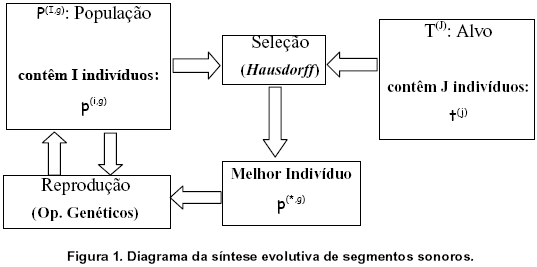
Onde:
p(i,g) : i-ķsimo indivĒduo da g-ķsima gerańŃo. Todos os indivĒduos sŃo composto por N pontos de ßudio monof¶nico, amostrados Ó uma taxa de amostragem Fs Hz e resoluńŃo b bits. Valores tĒpicos sŃo: Fs=44.1KHz e b=16 bits.
p(*,g) : o melhor indivĒduo da g-ķsima gerańŃo
P(I,g): g-ķsima gerańŃo do conjunto populańŃo de I indivĒduos. O conjunto populańŃo antes do inĒcio do processo evolutivo ķ denotado por P(I,0) .
T(J) : o conjunto alvo contendo J indivĒduos.
†(j): indivĒduos do conjunto alvo.
No processo de reproduńŃo agem dois operadores genķticos: crossover e mutańŃo. O crossover permuta segmentos de cada indivĒduo da populańŃo e o melhor indivĒduo. A mutańŃo insere modificań§es aleat¾rias em cada indivĒduo promovendo assim a diversidade da populańŃo. O grau de ańŃo dos operadores genķticos ķ dado pelas taxa alfa (taxa de crossover) e beta (taxa de mutańŃo). Valores tĒpicos utilizados sŃo: alfa=0,5 e beta=0.1.
No processo de seleńŃo, cada indivĒduo da populańŃo ķ comparado com todos os indivĒduos do conjunto alvo, atravķs de uma funńŃo de adequańŃo (fitness function). No mķtodo SESS, esta comparańŃo ķ feita pela distŌncia de Hausdorff que mede a distŌncia entre conjuntos atravķs da norma euclidiana (L2) tomada como sendo o MĒnimo do conjunto que contem todas as distŌncias tomadas entre cada elemento dos dois conjuntos. ĀA aplicańŃo de Hausdorff para sĒntese de som, no sentido de medir a similaridade entre conjuntos de amostras sonoras, ķ um desenvolvimento original deste trabalho. Outros pesquisadores como [Polansky, 1996], utilizaram processos de medida similares, chamados de mķtricas morfol¾gicos. Todavia, as medidas de similaridade foram tomadas entre conjuntos representados por eventos como notas, padr§es rĒtmicos e perfis mel¾dicos.
3. O Experimento
Foram realizadas 8 simulań§es da sĒntese evolutiva de segmentos sonoros, onde usamos diferentes tipos de indivĒduos tanto na populańŃo quanto no alvo. Como: senoides e ondas quadradas, em diferentes alturas (ou pitch). O resultado da sĒntese ķ a seq³Ļncia gerada pelo processo de evoluńŃo do melhor indivĒduo de cada gerańŃo da populańŃo de segmentos sonoros. ĀNas simulań§es realizadas o som sintetizado ķ apresentado como uma seq³Ļncia resultante do entrelańamento (overlap-and-add) de cada segmento sonoro que corresponde a cada melhor indivĒduo.
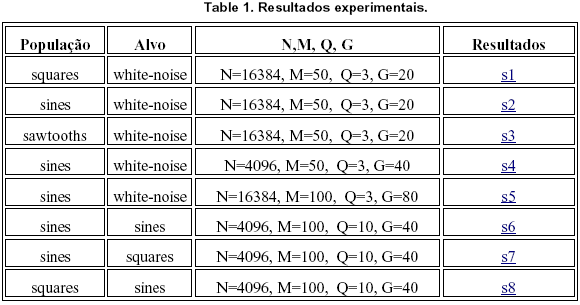
Onde:
alfa = 0.5 (taxa de crossover)
beta = 0,1 (taxa de mutańŃo)
Fs = 11025 (taxa de amostragem)
b= 16 bits (resoluńŃo da amostra)
N: comprimento de todos os indivĒduos, onde: tempo = N / fs [s]
M: n·mero de indivĒduos na PopulańŃo, onde indivĒduos estŃo espalhados em uma escala logarĒtmica entre fmin = 80Hz e fmax = 4KHz.
Q: n·mero de indivĒduos do Alvo.
G: n·mero de gerań§es da sĒntese evolutiva.
Todos estes resultados sonoros estŃo disponĒveis para download (em formato MP3) no link: http://nics.unicamp.br/~fornari/essynth1. A coluna ōResultadosö descreve o nome do arquivo sonoro disponĒvel na web.
4. ConclusŃo e comentßrios finais
Consideramos que a proposińŃo da sĒntese evolutiva de segmentos sonoros (SESS) fornece bases para a criańŃo de uma nova metodologia para desenvolver sĒnteses sonoras que nŃo sŃo determinĒsticas, mas evolutivas. O termo evolutivo ķ aqui utilizado no sentido de fazer uma analogia Ó EvoluńŃo Biol¾gica. Neste sentido, evoluńŃo sonora descreve um processo no qual uma populańŃo inicial de sons se aproxima gradativamente de outra, denominada de Alvo. ĀA sĒntese evolutiva de fato gera sons com grande riqueza de padr§es a partir de sons simples (tais como populań§es descritas por formas de ondas senoidais). Entendemos que o controle da SESS ķ intuitivo, pois ķ dado apenas pela manipulańŃo dos indivĒduos do conjunto alvo, que determina o curso da evoluńŃo das gerań§es de melhores indivĒduos. Ou seja, o processo de sĒntese ķ guiado por amostras sonoras e nŃo por valores numķricos ou parŌmetros. Nesta fase inicial o SESS, apesar de apresentar resultados sonoros interessantes, o mķtodo, do ponto de vista computacional, ķ ainda bastante simples. Muito pode ser desenvolvido uma vez que este ķ um campo praticamente novo e inexplorado de mķtodos de sĒntese sonora.
Como sugest§es para trabalhos futuros, temos, entre outras, as que se seguem: InclusŃo do conceito de genes e cromossomos dados por parŌmetros que descrevam o comportamento perceptual do segmento sonoro, como grandezas psicoac·sticas. InclusŃo do conceito de gĻnero nos indivĒduos, o que leva Ó criańŃo de um novo processo de reproduńŃo (sexuada). Variabilidade do n·mero de indivĒduos na populańŃo, que abre possibilidades para conceitos de extinńŃo ou explosŃo demogrßfica. InclusŃo de um perĒodo de maturańŃo do indivĒduo (participando do processo de seleńŃo, mas nŃo do de reproduńŃo), ou seja, infŌncia.
6. Agradecimentos
GostarĒamos de expressar nosso apresso Ó FAPESP, pelo apoio financeiro ao desenvolvimento deste trabalho, atravķs de bolsa de Pos-Doc no Brasil, processo: 04/00499-6, o que culminou em um pedido de patentes protocolado no INPI em 23 de Marńo de 2005, sob o n·mero: PI0500958-8 (Patente Requerida).
7. ReferĻncias
Fornari, J., Manzolli, J., Maia Jr., A., Damiani F., (2001) ōWaveform Synthesis Using Evolutionary Computationö. Proceedings of the V Brazilian Symposium on Computer Music, Fotaleza.
Fornari, J., Manzolli, J., Maia Jr., A., Damiani F., (2001) ōThe Evolutionary Sound Synthesis Methodö. SCI conference. Orlando, USA.
Manzolli, J., Moroni A., Von Zuben F.,Ā Gudwin R., (1999) ōAn Evolutionary Approach Applied to Algorithmic Compositionö, Proceedings of the VI Brazilian Symposium on Computer Music, Rio de Janeiro, Brazil, p. 201-210.
Manzolli, J., Fornari, J., Maia Jr., A., Damiani F., (2001) ōThe Evolutionary Sound Synthesis Methodö. Short-paper.Ā ACM multimedia, ISBN:1-58113-394-4. USA.
Moroni, A., Manzolli, J., Von Zuben, F., Gudwin, R., (2000) ōVox Populi: An Interactive Evolutionary System for Algorithmic Music Compositionö, Leonardo Music Journal, San Francisco, USA, MIT Press, Vol. 10.
Polansky, L.,1996., Morphological Metrics, Journal of New Music Research, 25, pp. 289-368.